
El objetivo principal de GDPR es fortalecer la seguridad y la protección de la privacidad de las personas. Mientras que GDPR comparte muchos principios de sus predecesores, que consta de 11 capítulos, 99 artículos y 187 considerandos, no es de ninguna manera una adaptación menor.
¿Quién esta sujeto a la GPRD?
El GDPR impone obligaciones legales a todos los controladores y procesadores de datos. se llama controlador de datos como la entidad que determina los propósitos y los medios de procesamiento de los datos personales, el procesador de datos se define como la entidad que procesa los datos personales en nombre del controlador. La GDPR se aplica al procesamiento llevado a cabo por organizaciones dentro del La UE y las organizaciones fuera de la UE que procesan o controlan los datos relacionados con residentes o nacionales de la UE.Se centra principalmente en datos individuales, que se define en dos categorías de "Datos personales" y "datos personales confidenciales". Los datos personales incluyen datos tales como direcciones de correo electrónico y físicas, así como cualquier información que pueda usarse como un identificador en línea, una dirección IP. Los datos personales confidenciales arrojan una mayor neto y cubre elementos de datos tales como datos de salud, biométricos o genéticos.
Si todavía no cuenta con las herramientas y controles de seguridad necesarios, su la organización tendrá que implementar varios controles de seguridad nuevos, políticas, y procedimientos para demostrar el cumplimiento de GDPR. Por seguridad y organizaciones conscientes de la privacidad, la nueva regulación no debería provocar demasiado mucha sobrecarga técnica Para aquellos que aún no han logrado el cumplimiento de las leyes de protección de datos que GDPR reemplaza, el impacto será mucho mayor.
La GDPR requiere que las organizaciones mantengan un plan para detectar una violación de datos, evaluar regularmente la efectividad de las prácticas de seguridad y documentar evidencia de cumplimiento. En lugar de una dirección técnica específica, la regulación pone la responsabilidad en las organizaciones para mantener las mejores prácticas para la seguridad de los datos.

Punto1: Implementar una herramienta de Información de Seguridad y Gestión de Eventos con gestión de registros capacidades que cumplen con los requisitos de cumplimiento.
El Artículo 30 del GDPR establece que cada controlador y, cuando corresponda, el representante del controlador deberá mantener un registro de actividades de procesamiento bajo su responsabilidad.
Un SIEM (Herramienta de Información de Seguridad y Gestión de Eventos) suele ser una herramienta de seguridad fundamental para muchas organizaciones. Al implementar un SIEM, las compañías pueden monitorear a todos los usuarios y actividad del sistema para identificar el comportamiento sospechoso o malicioso. Esto se logra centralizando registros de aplicaciones, sistemas y establecer una red y correlacionar los eventos para alertar dónde se detecta actividad indeseable.
A continuación, puede investigar la causa de la alarma y crear una vista de lo que ocurrió al determinar si un método de ataque en particular se utilizó, mirando los eventos relacionados, la dirección IP de origen y destino, y otros detalles. También debe tener en cuenta los datos almacenados o procesados en entornos de nube. Si los datos personales están en la nube, están dentro del alcance de GDPR, y por lo tanto es beneficioso elegir un SIEM que pueda mantener un registro de actividad en su nube pública y privada infraestructura, así como en las instalaciones.
Preguntas a responder:
- ¿Tiene una forma de centralizar, analizar y almacenar datos de registro de todos sus entornos?
- ¿Está alertado en tiempo real sobre cualquier actividad sospechosa o anómala?
- ¿Tiene una forma de almacenar de forma segura los datos de registro sin formato y para garantizar su integridad?
Solución con OracleLa interfaz de Audit Vault Server proporciona resúmenes gráficos de alertas. Estos incluyen un resumen de la actividad de alerta y las principales fuentes por cantidad de alertas. Puedes mediante un clic en los gráficos de resumen, acceder a informes más detallados. Para informar, las alertas se pueden agrupar por
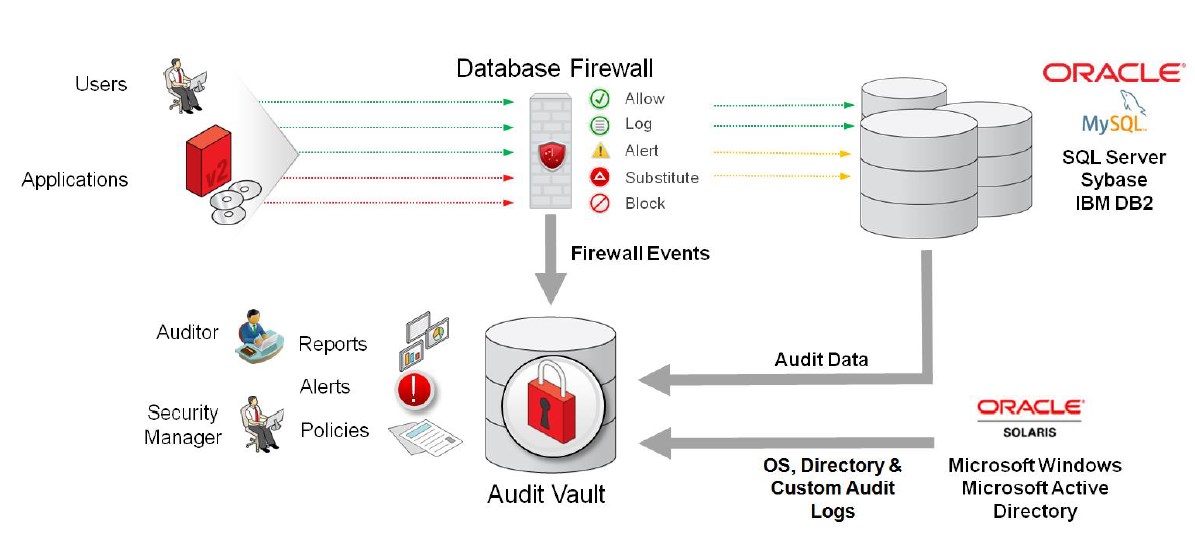
Un ejemplo de solución SIEM de terceros es HP ArcSight Security Information Event Management, que es un sistema centralizado para registrar, analizar y administrar mensajes de diferentes fuentes. Audit Vault Server reenvía mensajes al sistema ArcSight SIEM desde los componentes Audit Vault Server y Database Firewall.
Integración Oracle Audit Vault - Remedy y ArcSightIntegrar Oracle Audit Vault y Remedy Ticket System Solo se puede configurar un servidor Remedy para cada instalación de Oracle Audit Vault. Después de que se haya configurado la interfaz, un auditor de Audit Vault necesita crear plantillas para mapear y manejar los detalles de la alerta. Integración HP ArcSight No se necesita ningún software adicional para integrarse con ArcSight. La integración se realiza a través de configuraciones en la consola de Audit Vault Server. Los mensajes enviados a ArcSight SIEM Server son independientes de cualquier otro mensaje enviado desde Audit Vault (por ejemplo, feeds de Syslog). Hay tres categorías de mensajes enviados:
|

Punto 2: crea un inventario de todos los activos críticos que almacenan o procesan datos confidenciales para permitir para controles más estrictos que se aplicarán.
El GDPR es expansivo y cubre todos los sistemas de TI, redes y dispositivos, incluidos los dispositivos móviles. Por lo tanto, es esencial que hace un inventario de todos los activos en su infraestructura y establece dónde se guardan los datos personales.
Es importante inventariar todos los activos y ubicaciones que procesan o almacenan datos personales, una tarea que parece simple en su superficie, pero a menudo es un área donde las organizaciones luchan. Esto es especialmente cierto en entornos de TI dinámicos, como la nube pública y en casos donde los empleados están usando BYOD o activos no aprobados por IT. Vale la pena señalar que su empresa podría ser expuestos a ataques y multas reglamentarias si los empleados procesan o almacenan datos personales en dispositivos no aprobados.
Sin prácticas sólidas de gobierno en su lugar, puede ser fácil perder el control de los activos. Por tanto, es importante para muestrear sus sistemas, redes y almacenes de datos para determinar si los datos personales están expuestos fuera de los flujos y entornos de datos definidos. Tenga en cuenta que este es un proceso. Los inventarios necesita actualizarse constantemente a medida que cambia su negocio y tecnología.
Preguntas a responder:
- ¿Qué activos están conectados a mi entorno en un momento dado?
- ¿Estos activos procesan o almacenan datos personales?
- ¿Qué puertos y protocolos se usan al transmitir o acceder a información personal?
Solución con Oracle
Los sistemas DAM (Gestión de activos digitales) nos ayudan a controlar todo el ciclo de vida de las imágenes, documentos y ficheros multimedia. Nos ahorran inversión en TI ya que centralizan el repositorio de objetos facilitando el acceso mediante bancos, álbumes y vistas, logrando la eficiencia operativa de los usuarios en casi cualquier organización que emplee ficheros de imagen o audiovisuales como parte de sus procesos de negocio.
Oracle DIVAdirector es un sistema de administración de activos digitales que le brinda control total de los activos alojados en Oracle DIVArchive a través de una interfaz familiar, de modo que puede ubicar, acceder y administrar rápidamente los medios.

Mediante este producto podrás:
|

Punto 3: Emprender el escaneo de vulnerabilidades a identificar dónde existen debilidades que podrían ser explotado.
La verdad sea dicha descubrimos y lo más preocupante, los atacantes descubren nuevas vulnerabilidades en sistemas y aplicaciones surgen casi diario. Por lo tanto, es esencial que su organización se mantenga alerta. Estas vulnerabilidades pueden existir en:- El software (Java, PHP, Javascript y que decir de nuestro querido .NET)
- Configuración del sistema (Base de datos, servidor de aplicaciones, servidor web)
- En lógica de negocios. (BPM, SOA)
- En lógica de procesos.
La evaluación efectiva de la vulnerabilidad requiere el escaneo continuo y el monitoreo de los activos críticos sobre los cuales los datos personales reside o es procesado. Es igualmente importante monitorear los entornos de la nube además de los entornos locales.
Al descubrir una vulnerabilidad, nos tenemos que preguntar:
- ¿Cuántos registros personales podrían estar expuestos?
- ¿Se han intentado intrusiones o exploits en el activo vulnerable?
- ¿Cómo es explotada la vulnerabilidad por los atacantes en la naturaleza?

Punto 4: Realice evaluaciones de riesgos y aplique modelos de amenazas relevantes para su negocio.
El artículo 35 del GDPR requiere que las organizaciones realicen una evaluación de impacto de la protección de datos (DPIA) o similar. Considerando que el artículo 32 de la regulación requiere que las organizaciones "implementen medidas técnicas y organizativas apropiadas para asegurar un nivel de seguridad apropiado para el riesgo ".
El uso de un marco de seguridad de la información puede ayudar proporcionando un punto de partida para que las organizaciones comprendan mejor los riesgos que enfrenta el negocio. Los marcos existentes como NIST, ISO / IEC 27001 o estándares similares pueden ayudar a las empresas en emprender y apoyar el proceso DPIA.
Si bien GDPR no especifica un marco para las evaluaciones de riesgo o el modelado de amenazas, una empresa el cumplimiento de cualquier norma bien establecida e internacionalmente reconocida demostrará el cumplimiento de los artículos 32 y 25 es mucho más probable en caso de incumplimiento.
Preguntas a responder:
- En caso de una violación de datos, ¿puedo demostrar que se implementaron los controles de seguridad adecuados?
- ¿Sé a qué amenazas se enfrenta mi organización y la probabilidad de que se materialicen?
- ¿Estoy al tanto de qué sistemas y unidades de negocios son de alto riesgo?

Punto 5: Realice pruebas regularmente para asegurarse de que los controles de seguridad funcionan según lo previsto.
El artículo 32 de la GDPR cubre la seguridad del procesamiento de datos personales. Entre los ejemplos que proporciona, se solicita un proceso para regularmente probando, evaluando y evaluando la efectividad de las medidas técnicas y organizativas para asegurar seguridad del procesamiento.
Evaluar y evaluar la efectividad de los controles de seguridad no es una hazaña fácil. Por lo general, cuanto mayor es el entorno TI, cuanto más dispares sean las pilas de tecnología, y cuanto más complejo sea el entorno. Por lo tanto, más difícil es ganar garantía.
Existen tres amplias técnicas para validar la efectividad de los controles de seguridad:
- Manual de cumplimiento. Esto implica auditorías, revisiones de aseguramiento, pruebas de penetración y actividades del Equipo Rojo (el término Equipo Rojo se usa tradicionalmente para identificar a grupos altamente calificados y organizados que actúan como rivales ficticios).
- Productos de seguridad integrados y consolidados, de modo que es necesario administrar e informar menos productos puntuales.
- El uso de tecnologías de aseguramiento automatizadas.
Con estos métodos, puede obtener una medida de seguridad de que sus sistemas
están asegurados según lo previsto. Sin embargo, vale la pena recordar que la seguridad no es un esfuerzo de una sola vez, sino un proceso continuo y repetible.
Preguntas a responder:
- ¿Qué nivel de confianza tiene en sus herramientas de seguridad?
- Si una herramienta o sistema falla, ¿se alertaría automáticamente?
- ¿Se están utilizando todas las herramientas de seguridad como se ha definido?

Punto 6: Implemente controles de detección de amenazas para informarle de manera oportuna cuando ocurra una infracción.
La GDPR requiere que las organizaciones informen al organismo regulador dentro de las 72 horas de estar al tanto de la infracción. Para alto riesgo eventos, el controlador debe notificar a los interesados sin demora indebida (Artículo 31). El tiempo de compromiso típico continúa midiéndose en minutos, mientras que el tiempo de descubrimiento permanece en semanas o meses, en tales circunstancias, es esencial tener capacidades integrales de detección de amenazas que puedan detectar problemas tan pronto como ocurren.
Las amenazas pueden materializarse internamente en la empresa (normalmente) o externamente. Pueden estar en las instalaciones (on premise) o en entornos de nube (on cloud). Por lo tanto, es importante poder recopilar y correlacionar eventos rápidamente; y complementa la información con inteligencia de amenazas confiable para estar al tanto de las amenazas emergentes.
No hay un solo lugar o herramienta que sea apto para todos los propósitos. A veces se descubre una amenaza en el punto final, el perímetro o analizando el tráfico interno. Por lo tanto, los controles deben colocarse en consecuencia en el ambiente para aumentar la probabilidad de detectar amenazas tan pronto como ocurran.
Preguntas a responder:
- ¿Podrás identificar y responder a una violación tan pronto como ocurra?
- ¿Conoce los tipos de ataques a los que su empresa está sometida?
- ¿Conocen los empleados cómo informar una infracción?

Punto 7: Supervisar el comportamiento de la red y del usuario para identificar e investigar incidentes de seguridad rápidamente.
La GDPR se centra en garantizar que los datos de los ciudadanos se recopilen y utilicen de manera adecuada para los fines que se establecieron. Por lo tanto es importante enfocarse no solo en amenazas externas o malware, sino también para detectar si los usuarios están accediendo a los datos adecuadamente.
El contexto es crítico cuando se evalúa el comportamiento del sistema y la red. Por ejemplo, una gran cantidad de tráfico de Skype en la red utilizada por su equipo interno de ventas es probablemente una parte normal de las operaciones. Sin embargo, si el servidor de la base de datos alberga su lista de clientes de repente muestra una explosión de tráfico de Skype, algo es probable que esté mal.
Hay muchos métodos que se pueden implementar para monitorear patrones de comportamiento. Un método es utilizar el análisis de NetFlow, que proporciona las tendencias de alto nivel relacionadas con qué protocolos se usan, qué hosts usan el protocolo y el ancho de banda uso. Cuando se utiliza en conjunto con un SIEM, puede generar alarmas y recibir alertas cuando su NetFlow va por encima o debajo de ciertos umbrales.
Preguntas a responder:
- ¿Sabes cómo se ve el tráfico "normal" en tu red?
- ¿Sería capaz de detectar si un usuario legítimo está extrayendo datos de clientes?
- ¿Un aumento o caída en el tráfico elevará las alarmas?

Punto 8: Tener un plan de respuesta a incidentes documentado y practicado.
Para cumplir con las regulaciones de GDPR, las organizaciones deben tener un plan para detectar y responder a una potencial violación de datos para minimizar su impacto en los ciudadanos de la UE. En el caso de un ataque o intrusión, un proceso simplificado de respuesta a incidentes puede ayudarlo a responder de manera rápida y eficaz para limitar el alcance de la exposición.
Si tiene procesos y controles unificados de detección de amenazas para alertarlo sobre un incidente, su plan de respuesta a incidentes debe poder determinar de forma rápida y precisa el alcance del impacto. Debe investigar todos los eventos relacionados en el
contexto de otra actividad en su entorno de TI para establecer una línea de tiempo, y la fuente de ataque debe ser investigada para contener el incidente.
Una vez que haya contenido el incidente, debe evaluar si se produjo una posible infracción de los datos personales y decidir si se requieren informes según GDPR. Luego, debe priorizar y documentar todas las tácticas de respuesta y reparación. Asegúrese de verificar que las actividades de respuesta a incidentes hayan solucionado correctamente el problema. Tendrá que informar al regulador de todos los pasos dados y, cuando sea necesario, informar a los ciudadanos de la UE afectados.
Preguntas a responder:
- ¿Están todas las partes relevantes informadas y conscientes de qué hacer en caso de un incidente?
- ¿Se practica el plan de respuesta a incidentes para garantizar que funcione en escenarios del mundo real?
- ¿La documentación está completa y actualizada?

Punto 9: Tener un plan de comunicación para notificar a las partes relevantes.
En caso de incumplimiento, su organización debe informar al organismo regulador dentro de las 72 horas de haber tenido conocimiento de la infracción. Para eventos de alto riesgo, el responsable del tratamiento debe notificar a los interesados sin demora (Artículo 31).
La notificación a la autoridad que supervisa la GDPR, en cada país, es requerida por lo menos para:
- Descripción la naturaleza de la violación.
- Proporcionar el nombre y los datos de contacto del responsable de protección de datos de la organización, normalmente el CSO.
- Describir las posibles consecuencias de la violación.
- Describir las medidas tomadas o propuestas a tomar por el controlador de datos para abordar la violación y mitigar sus efectos adversos.
Preguntas a responder:
- ¿Puedo identificar si los sistemas en el alcance de GDPR se ven afectados en una violación?
- ¿Tengo los detalles de contacto del organismo regulador que debo notificar?
- Si es necesario, ¿tengo un mecanismo confiable para contactar a los clientes afectados?







